

Contents [hide]
Data Wrangling: Turning Raw Data into Actionable Insights
Data analytics and science require data munging or purification. It involves formatting raw data for analysis. The idea is simple, but executing it needs a deep grasp of the data’s structure, context, and analysis aims. This article discusses data wrangling’s importance, methods, problems, and best practices.
What is Data wrangling?
Data wrangling cleans, restructures, and enriches raw data for analysis. In data analysis, data science, and machine learning, data quality and organization are key to insights. Text, statistics, photos, and log files from sensors, websites, and databases are examples of raw data.
Wrangling prepares data for statistical models, machine learning algorithms, and business intelligence tools. It is crucial because accurate analysis requires high-quality data, and even advanced algorithms would fail without good wrangling.
The Value of Data Wrangling
In today’s data-driven world, corporations collect massive amounts of data from many sources. But raw data is often untidy, fragmentary, inconsistent, or wrong. Missing values, outliers, duplicates, and discrepancies may be present. This requires data wrangling.
Data wrangling is crucial for these reasons:
Data Quality Assurance: Analysis requires clean data. Unreliable outcomes result from data errors.
Improvements in Decision-making Wrangling organizes raw data for analysis and interpretation. Actionable insights inform better judgments.
Enhanced Efficiency: Data wrangling organizes and simplifies data, saving analysts and data scientists time.
Enhanced Model Performance: Data quality is crucial to machine learning and predictive modeling. Wrangling ensures training and evaluation data format.
Data Wrangling Steps
Data wrangling has numerous steps. The following steps are typical, however they may vary depending on project data and goals:
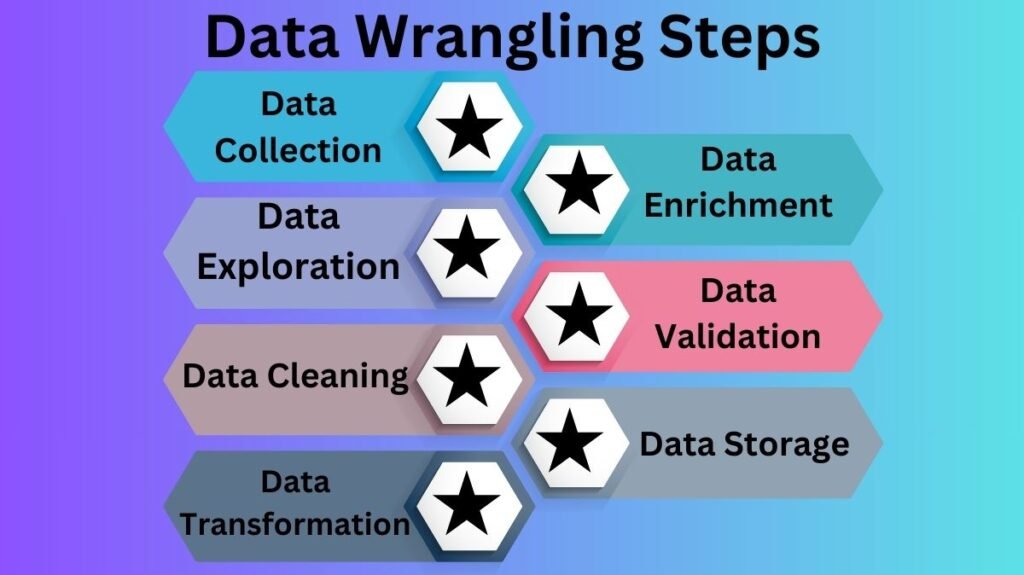
Data Collection: Data wrangling begins with data collection from multiple sources. Databases, flat files (CSV or Excel), online scraping, APIs, and real-time sensor or device data feeds are examples.
Data Exploration: After collecting data, explore it to discover its structure, patterns, and concerns. Analyzing data, displaying distributions, and finding anomalies are data exploration.
Data Cleaning:Often the longest part of wrangling is data cleaning. Missing numbers, duplicates, outliers, mistakes, and inconsistent data formats are involved. There are many data cleansing methods:
- In some cases, missing data can be managed by eliminating the affected records, filling in missing values with the mean/median/mode, or using more advanced methods like interpolation or imputation.
- Removing Duplicates: Duplicate rows or items distort analysis and should be eliminated or merged.
- Standardizing Formats: Dates and currency values may be in different formats. Format standardization ensures uniformity.
Data Transformation: After cleansing, data is transformed into an analysis-ready format. This may involve:
- Normalizing Data: Scaling numerical values to fit a range or distribution.
- Encoding Categorical Data: One-hot or label encoding is used to convert categorical data into numerical values for analysis or machine learning.
- Aggregation: Grouping values to calculate average sales per region.
Data Enrichment:Additional data sources can be added to enrich the dataset. Joining foreign datasets, adding calculated characteristics, or generating new variables from data are examples.
Data Validation:Validating modified data is essential after wrangling. This phase confirms that the data matches the format and that no data was lost or altered during wrangling.
Data Storage:Last, clean and converted data should be stored efficiently and easily. It may be loaded into a database, data warehouse, or cloud storage platform.
Data Wrangling Methods
Different methods, tools, and computer languages are used for data wrangling. Methods vary by data type and goals. Some common data wrangling methods:
Pandas (Python):One of the most popular Python data manipulation and wrangling libraries is Pandas. DataFrames and Series simplify data manipulation, cleaning, and analysis. Data can be filtered, aggregated, merged, and reshaped using the library.
SQL: SQL is frequently used to query and manage relational database data. SQL’s ability to filter, join, and aggregate data makes it crucial for database management.
Spreadsheets: Excel is still useful for small to big datasets. VLOOKUP, pivot tables, and conditional formatting speed up data cleaning, analysis, and visualization.
R:R is another prominent data science and statistical analysis computer language. Several programs, like as dplyr and tidyr, help clean and organize data.
OpenRefine: Powerful open-source data transformation tool. This helps unorganized, messy data.
ETL Tools:Wrangling massive amounts of data from several sources requires ETL tools like Apache Nifi, Talend, and Alteryx.
Data Wrangling Challenges
Despite its importance, data wrangling is difficult. Common obstacles are:
Inconsistent Data Formats:Standardizing data is problematic due to its inconsistent formats, such as dates in MM/DD/YYYY vs. DD/MM/YYYY.
Missing Data:Real-world datasets often have missing values. Depending on the context, impute missing data, drop rows, or leave them as-is can be difficult.
Large Datasets:To minimize performance difficulties, huge datasets must be wrangled efficiently. Data volume may require specialist tools or parallel processing.
Data Quality Issues: Typographical errors, inaccurate labels, and outliers may require rigorous cleaning to maintain correctness.
Time constraints: Data wrangling takes time, and analysts may be under pressure to clean and process data rapidly, which can lead to errors or oversights.
Data Wrangling Best Practices
Following these excellent practices during wrangling will yield the best results:
Automation: Create reusable scripts for repetitive operations like data extraction and cleaning to reduce human error.
Record the Process: Document data wrangling steps. This documentation will ensure process openness and reproducibility.
Quality above Speed: Clean data first. Even though it takes longer, clean, high-quality data yields superior outcomes.
Test the Data:Use data validation, consistency tests, and outlier identification to verify the data after wrangling.
Use Version Control: Teams should use Git to track changes and avoid confusion when wrangling data.
Conclusion
Data wrangling is essential and laborious in data analysis. It’s time-consuming, yet necessary to ensure data accuracy, consistency, and analysis. A good data wrangling method can help you get useful insights in machine learning, business intelligence, and other data-driven fields. Organizations and data professionals may use clean, structured data to improve decision-making and outcomes with the correct tools, approaches, and best practices.